This is a story of a messaging app used by billions of users.
The app followed an extremely strong model of privacy. The app never persisted the user’s data on the servers. All the communication is end-to-end encrypted.
A lot of users of this app, especially, on Android would regularly uninstall and reinstall the app. Now, to prevent these users from losing messages, the messages were backed up to the user’s SD card. In the Android security model, an SD card is a public storage space, accessible to all apps. So, to keep messages private, the backups were encrypted.
Now, suddenly, there was a spike in complaints from users about the app failing to restore their messages. While we had some internal metrics to confirm this, there was no way to debug what happened without access to some samples for reproduction. For a messaging app user, especially ours, messages were memories. Losing messages was losing valuable memories.
We reached out to the users for sample backups to reproduce the problems. And a few replied. All samples were cryptographically fine.
The SQLite database in the backup, however, was broken.
They would neither load via Sqlite on Android nor via any Sqlite browser on Mac OS.
However, one could open them up in
SQLite Shell.
And as long as the queries don’t try to touch the broken row, they would succeed as well.
Even aggregate queries like SELECT COUNT(*) worked.
In one case, primary key constraints were being violated. In a few other cases, there were incorrect Unicode characters. While I tried to dig in, I was not able to find a reason for these. The low-end Android phones are a weird beast. I saw enough memory faults regularly that these database corruptions didn’t surprise me either.
But how do we find and eliminate such corrupted entries programmatically?
RTFM - Read the full manual
I kept reading the SQLite Shell manual again and again. Till I realized that I could, in principle, dump the SQLite database into a sequence of SQL commands that faithfully reproduces the database.
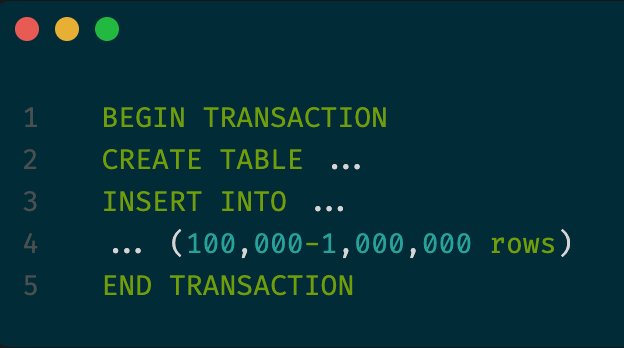
The dump looked like this.
| |
And this dump worked even for those broken databases!
We decided that losing a few bad messages to recover everything else would be an acceptable trade-off. But how?
What if I could identify bad rows and remove them? The user’s messages contain newlines, so, I cannot neatly separate out those commands. And since everything was in a transaction, it was rolled back as soon as the first error occurred.
As I kept digging into the manual, I found
| |
Voila!
Fix
The final process looked something like this. The user goes into the normal database restore and if it fails, we fall to the following.
| |
This happened whenever the user encountered a corruption in their database and finished within 5-60 seconds.
It indeed worked
Remember that aggregate queries to count work even when the database seems to be corrupted. So, we knew that we could count rows in the corrupted as well as the restored database.
Without revealing the precise number, I can say that the results were pretty good, most users lost only a few messages during this recovery process, and almost the full database was recovered for most of the users.
The final database repair layer was ~200 lines of code. Probably, the smallest in the world. It is installed on billions of devices today, ready to rescue them from database corruption.